Last Updated
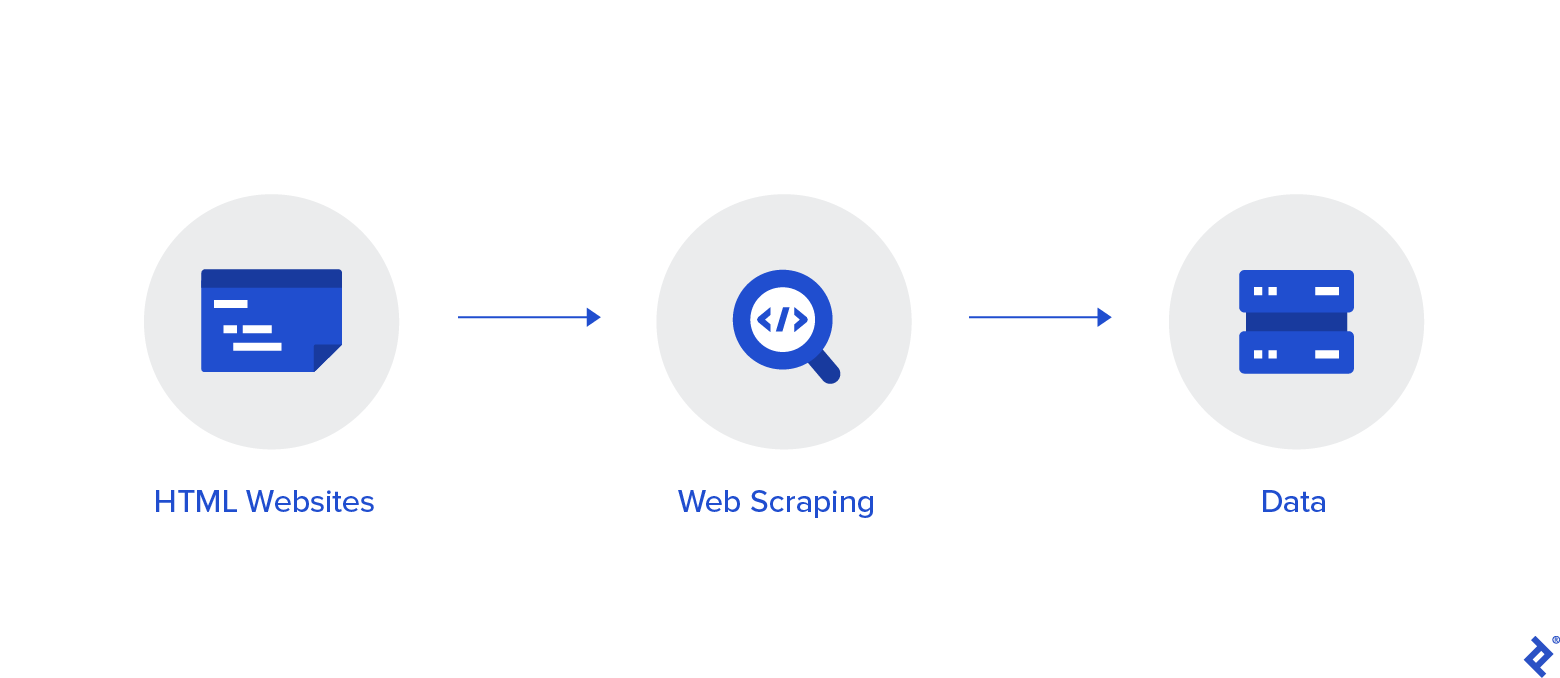
Description: Web scraping is a process where data is extracted from web pages using programs. It can be used for website scraping, email scraping, and social media scraping.
The
act of gathering, collecting, or extracting data from websites is known
as web scraping. This is typically carried out as a component of
programs or procedures used for different kinds of data collection
requirements.
Simply explained, web scraping is the process of copying extensive amounts of data from any internet source. Web scraping
uses automated techniques to collect thousands, millions, or billions
of pieces of information from the internet, as opposed to the laborious
process of gathering data manually. This is why a lot of companies use
the web scraping technique to get a lot of information that is pertinent
to their industry.
Although
automated methods are typically favored because of their speed, ease,
and reduced costs, web scraping can be done manually as well.
Web
scrapers are the name given to these automated technologies. Depending
on the type of website you want to scrape, these may have a different
set of functionalities.
There are different reasons behind the usage of web scraping, some of them are:
The
crawler, additionally known as a “spider”, works as a guide and leads
the scraper via the internet to locate the statistics that it wishes to
collect. The crawler searches for content, which the web scraper then
extracts from the websites crawled via by way of the crawler.
Web
scrapers function in a slightly complicated way. A website's structure
must be understood in order to extract the necessary data and export it
in a completely new format.
Most
of the time, web scrapers are given a specific URL (or a list) to
extract data from. Following that, the scraper will either take all the
data from the website or you may choose just the information you wish to
extract.
After that, the scraper will start working and allow the user to download the data in Excel or another format.
Web
scraping is a method of gathering or extracting data from websites. The
term web scraping is often used interchangeably with the term data
mining, although it's technically not the same thing. If you remember
your high school algebra class, you may recall that there are two main
types of equations: linear and quadratic. Web scraping is used to
describe a variety of techniques that can be used to extract information
from websites.
The most common uses for web scrapers
are data gathering and data extraction. Data gathering refers to using
web scrapers to gather information about users, their behavior, and the
products they use. Data extraction refers to using web scrapers to
gather information about user's interests and preferences so that
marketers can target them with relevant offers or advertisements.
ShiftProxy’s data center and ISP proxies are an ideal match for users looking for customizable, robust, and advanced proxies to carry out their web scraping jobs.
Found this post helpful? Here are some similar blogs that you may find interesting!
Thousands of people have trusted Shiftproxy along their web scraping journey.
Now it's time for you to try the best proxy provider on the market!
 Free Proxy List
Free Proxy List Proxy Checker
Proxy Checker ISP AT&T
ISP AT&T Datacenter
Datacenter