SHIFTPROXY
SHIFTPROXY Welcome to the Shiftproxy blog! We have plenty of informative content you may find interesting.
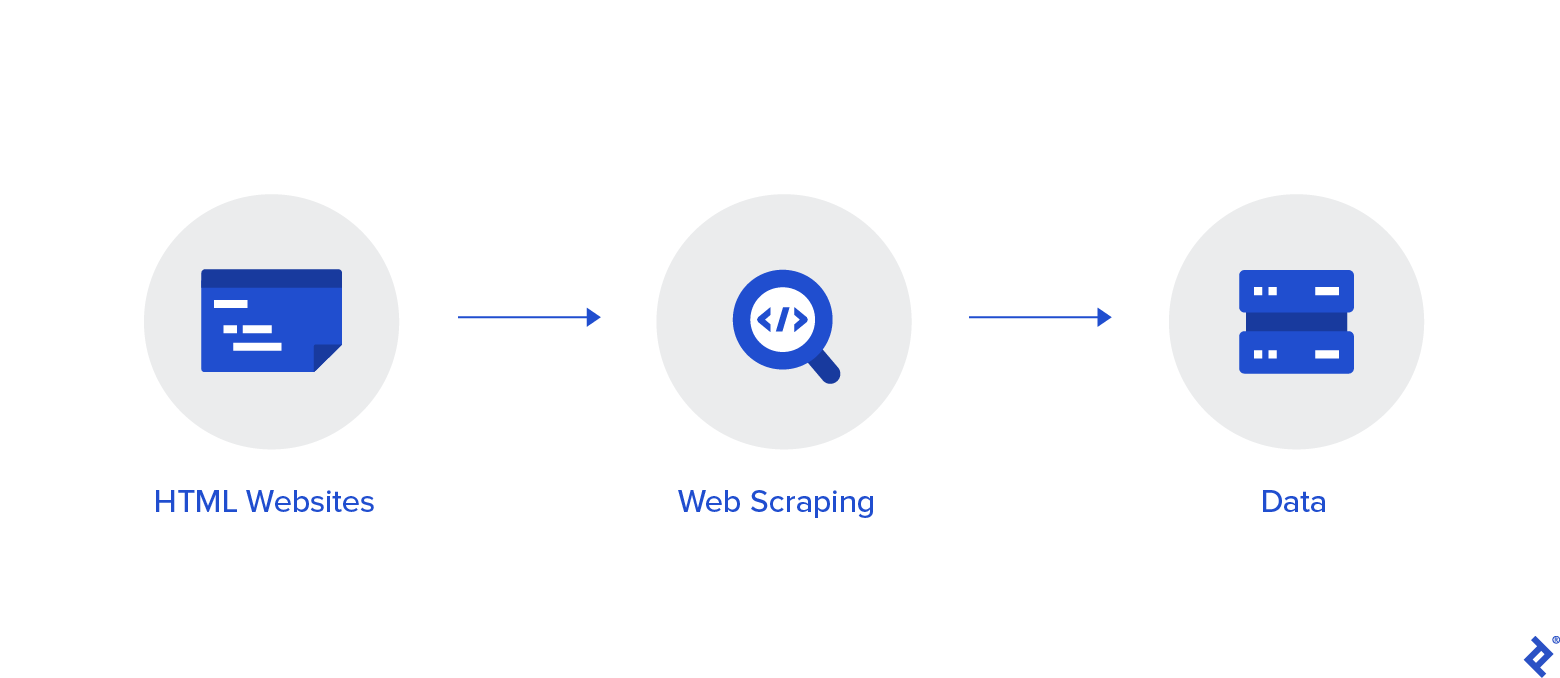
Thousands of people have trusted Shiftproxy along their web scraping journey.
Now it's time for you to try the best proxy provider on the market!
 Free Proxy List
Free Proxy List Proxy Checker
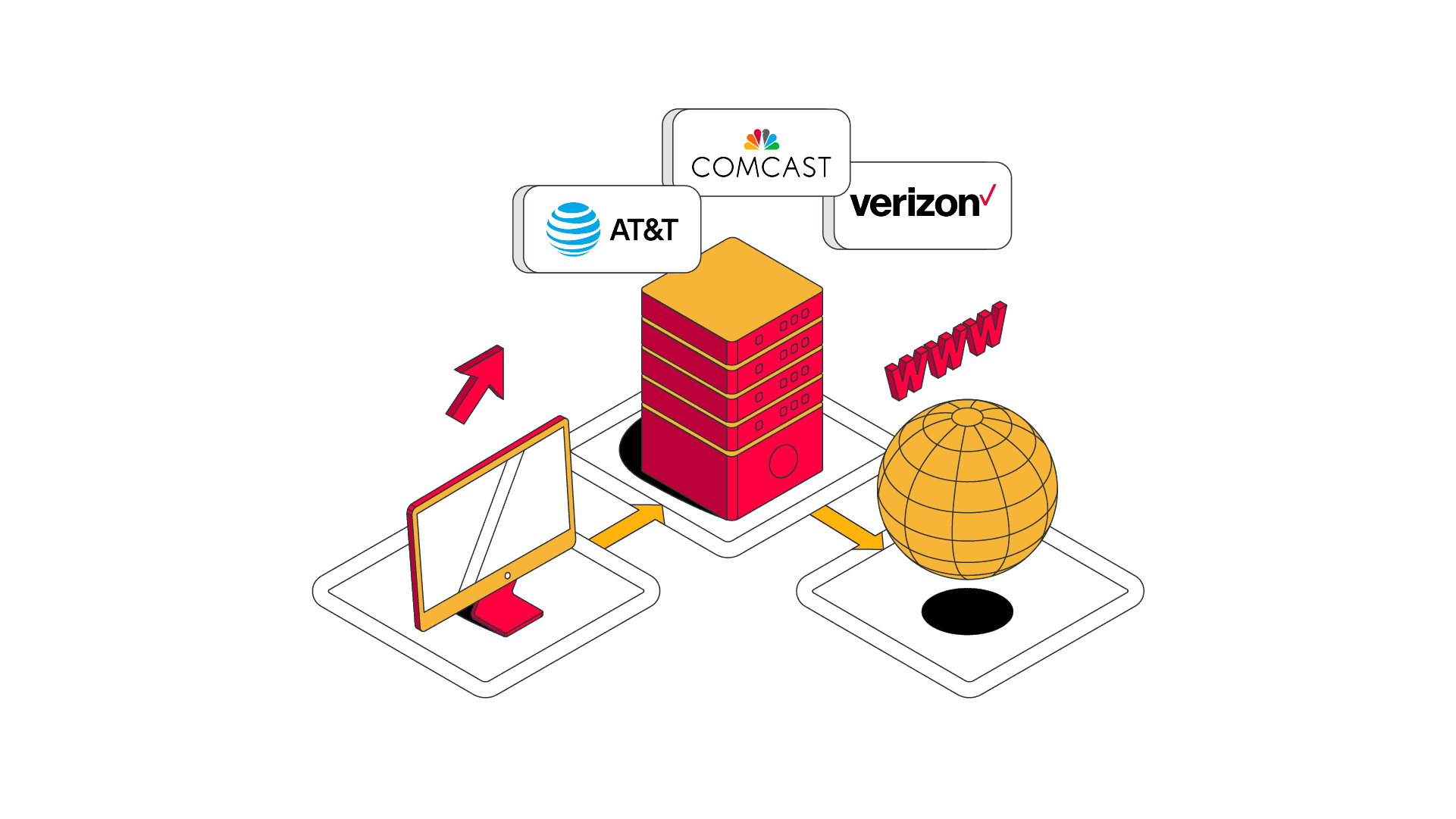
Proxy Checker ISP AT&T
ISP AT&T Datacenter
Datacenter